
Accessible AI - A Neural Algorithm of Artistic Style

An intuitive annotation of the style-transfer paper (Gatys et al. 2015) along with pseudocode to help bridge the gap between academia and industry.
Title: A Neural Algorithm of Artistic Style
Authors: Leon A. Gatys, Alexander S. Ecker, Matthias Bethge
Published On: 26 Aug 2015
Relevance
This paper introduces the concept of using a convolutional network to separate the content from the style in an image. The authors use the feature maps from specific Convnet layers as a minimization objective. Their findings also create new opportunities to analytically model the style and content representation in neurons.
Opinion
The main two points I'm excited about in this paper are: 1) The potential to separately model how neurons represent style and content in the eye. 2) The concept of using different feature spaces (i.e. feature maps) as an optimization objective.
high level overview
Generate a matrix of random data (z). Load a pre-trained VGG19 net. Give the VGG net z and an image x. Extract the feature maps (F_z and F_x) from a few different layers. Minimize the MSE between those feature maps to generate a content loss. Do the same for style loss but first calculate a Gram matrix for each feature map.
Combine both loses and optimize to render an image that captures the style of one image and the content of another.
ANNOTATIONS
Glossary (Non-exhaustive):
Convolutional network (ConvNet): Neural network that slides small filters over the previous input while multiplying (aka convolutions).
Source: stackexchange
VGG net: A ConvNet that was used to win a competition (imagenet). It's fully trained and you can download it from many places.
Gram matrix: Inner product of a matrix.
Feature map: what comes out of the layer of a ConvNet.
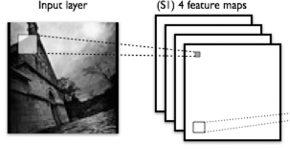
Source: deeplearning.net

Humans can make paintings but we don't have algorithms that can yet.
But... now ConvNets work, so we used them to create images that look "artistically" real.
Basically, we use Convnets to split the style (i.e. colors, strokes...) and the content (i.e. the house or whatever is in the image) from ANY two images, and then recombine the content and style to make "artistic" looking images...
Because ConvNets and the visual system seem to be similar, maybe this work helps us understand how humans create and see images.

Convolutional neural networks are a type of neural network that extract image information at different scales as the image moves through the layers of the network.
Basically, each layer pulls out information about the image in chunks of data called feature maps.
As a standard network is trained for object recognition, it learns to recognize different parts of the content as it goes through the layers. The first layer might learn about lines, and the last layer about people. We care about these last layers because they contain the content we want to make artistic.
We call these last layers the content representation.
To extract the style of an image (i.e. the stroke and colors), we calculate the correlation between the outputs of higher level layers. This calculation captures texture information in the image.

Picture of convolutional network.
The top row is the style extracted from an image by the network.
The middle is the convolutional network (here 5 layers)
The bottom is the content extracted from an image by the network.
The left are the input images to the network.
At the bottom we see that when we pull out the information from each layer, we get almost perfect images in the first layers, and mostly structural information in the higher layers.
**Note: A VGG net is talked about as having "blocks" each block may have multiple convolutional layers.
As an example, "conv1_2" means: Take the output of the SECOND convolution in the FIRST convolutional block.

The main point is that the style and content of an image when filtered through a ConvNet are separable. To show what they mean, the authors took an image from a place in Germany (as the content source) and applied the style from a few well known artists.
The result is that the content comes from the photograph and the style from the piece of art. The final image has the content of the photograph but the colours and structures come from the artwork.
Remember that the style is represented by information at different scales from multiple layers in the network.

Images of the same area in Germany with the style from 5 different painters.
The content here is the building + lake + sky and so on.
The style has the colors, strokes and weird circles or lines we find in each image from B-F.

Matched styles from higher levels of the network make smoother and nicer looking pictures.
Authors acknowledge that style and content cannot be 100% separated. So they frame their loss function in a way that minimizes two terms (the style term and content term).
+ example code to illustrate loss function
b = 0.7
style_heavy_loss = (a content_loss) + (b style_loss)
content_heavy_loss = (b content_loss) + (a style_loss)
The author's system (a neural network) can get pretty good results at separating the style from the content.
They show this through kick-ass images that look like these artists made these images.
They use another network (VGG network usually) to get the feature maps and they use those as inputs to their algorithm.

Left to right shows what happens when the a, b values change.
As x goes higher we see more of the image.
Top to bottom shows what kind of information lives in these 5 layers of the neural network.

People who tried this before did it with much simpler systems (humble brag).
Previous non-deep learning methods used pixel information to try to do the same (in computer vision this goal is called photorealistic rendering).
But they used non-parametric methods and not Convnets... In this case, Convnets capture higher level information instead of messing around with the individual pixels.
*Note: Non-parametric methods are statistical methods that don't assume your data are normally distributed (in the simplest form).
Back in the day (a few years ago), researchers used a similar concept to figure out when artwork was created (period, year, etc..). The authors here propose that their method MIGHT be better because they're working directly with the higher level features.
The authors stress that the ability to merge style and content allow researchers to study how art and style are represented in humans.
Their algorithm could potentially explain how neurons capture content or style of an image separately.
(!!!)

To neuroscientists:
Their analytical formula can test for the representation of images down to the single neuron level.
Style simply computes the correlation between neurons. Complex cells in the Visual system do a similar process.
They suggest performing complex-cell like calculations along different parts of the ventral stream as a way to get content information about a stimuli.
Pretty cool that the neural system (the network) can learn image representations that can separate content from style. They think it's because to classify objects well, the network has to become invariant to object representations (i.e. recognize a cat face whether it's upside down or not).
They used VGG19 network as their feature extractor.
BTW they recommend to use avg pooling instead of max-pooling to stabilize gradients.
**Note: this advise is likely not needed now if you use BatchNorm.

An image can be thought of as encoded by the activations of a layer in the Convnet.
Let x be the image
F be an N x M matrix with N filters and each filter having M entries (height * width).
filter_0 = [[0, 1, 0], [1, 0, 1], [0, 1, 0]] # (3, 3) filter
filter_1 = ...
F = [filter_0.flatten(), filter_1.flatten()] # shape (2, 9)
The point of this algorithm is to feed the network a matrix of random data (z), freeze the network and backprop into z while minimizing the distance as measured by the feature maps.
* Note: The two things that may sound weird are:
- NOT updating the network
- But this is the point... Because the network is the VGG which is already trained...
- Minimize MSE on FEATURE MAPS (not on pixels)
- The point is to capture high-level features. The authors use the feature maps to do this.
Algorithm to visualize a particular layer inside of the network :
#give the network random noise
x = np.random.random(64, 64, 3) # they swap their notation here :(
p = imread('german_place.jpg')
#get the feature maps for image and noise mtx
P_x = Convnet.get_layer_feat(x, layer='conv2_2')
F_p = Convnet.get_layer_feat(p, layer='conv2_2')
#calculate MSE loss in feature map space (eq 1)
conv2_2_content_loss = np.square(F_p - P_x).mean()

To capture the style of an image, the authors measure the correlation between the feature map of an arbitrary layer L_i (in our example we use VGG layer 'conv2_2'.
+ here we calculate the Gram Matrix
F_p_conv2_2 = Convnet.get_layer_feat(p, layer='conv2_2')
gram_mtx_conv2_2 = np.dot(F_p.T, F_p)
And can formulate the style loss as the MSE of the feature maps for all the layers we want
+ (eq 4, eq 5) MSE on Gram matrix of all layers
def gram_loss(layer_num, weight_factor): #(eq 4)
#give the network random noise
a = imread('german_place.jpg')
x = np.random.random(64, 64, 3) # they swap their notation here :(
#get the feature maps for image a and noise mtx p
A_a = Convnet.get_layer_feat(a, layer='conv2_2')
G_x = Convnet.get_layer_feat(x, layer='conv2_2')
#generate GRAM matrix for each feature map
Gram_A = np.dot(A_a.T, A_a)
Gram_G = np.dot(G_x.T, G_x)
#calculate MSE loss in GRAM mtx space (eq 1)
conv2_2_content_loss = np.square(Gram_G - Gram_A).mean()
return weight_factor * conv2_2_content_loss
#determine layers and the weight_factors for each
layers = ['conv1_1', 'conv2_1', ..., 'conv5_1']
weight_factors = [0.2, 0.3, ..., 0.1]
#calulate actual style loss for all layers (just sum) (eq 5)
style_loss = np.sum([gram_loss(layer_name, weight_factor) for layer_name, weight_factor in zip(layers, weight_factors)])

To build the fancy images with the content of a photo and the style of say... Picasso, we minimize the joint loss between content and style...
(eq 7) final loss function to mix style and content
alpha = 0.3
beta = 0.7
total_loss_fx = (alpha * content_loss) + (beta * style_loss)
#set up Adam optimizer
lr = 1e-4 # learning rate
train_op = tf.train.AdamOptimizer(lr).minimize(total_loss_fx)
#take one step of optimization
error = sess.run(train_op)
Mandatory Hinton reference



